Benchmark Study
This page is the benchmark dossier forgitquarry search. It is not just a run log. The goal is to answer the product questions that matter in practice:
- how much latency each option adds
- what that extra cost actually buys
- which modes preserve the native baseline versus deliberately breaking away from it
- when optional knobs such as README enrichment, weighted blends, recency, and language filters are worth using
api gatewayterminal ui
api gateway is noisy and infra-heavy. terminal ui is lexically cleaner and exposes whether a mode is adding useful semantic breadth or just drifting.
Executive Summary
- Native is still the only sub-second path. In this run it stayed around
~0.5sto~1.1s. - Quick discover adds
~15.7sto~18.3sover native. - Balanced discover adds
~26.8sto~30.1sover native. - Deep discover adds
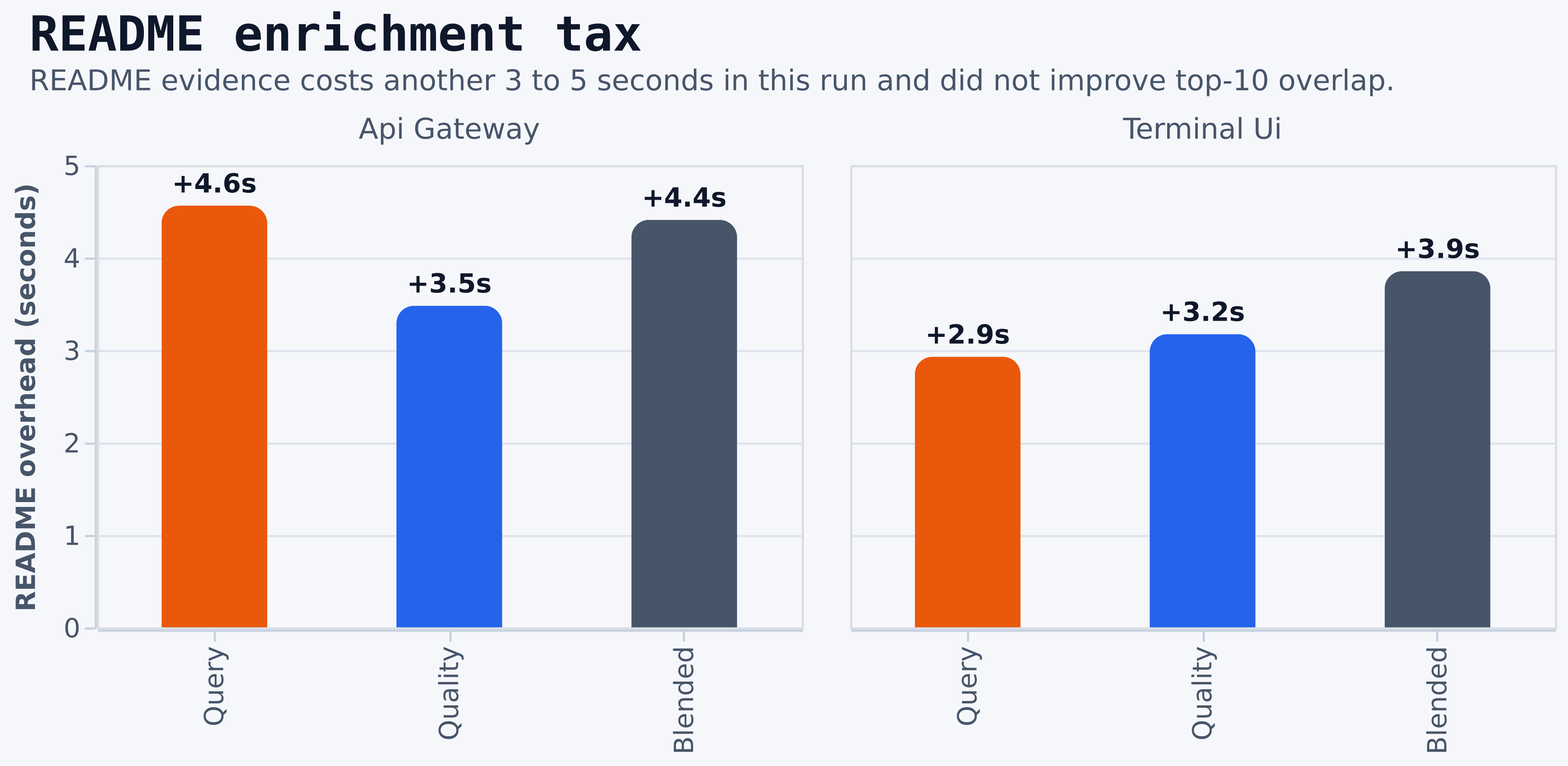
~52.5sto~59.8sover native. - README enrichment added another
~2.9sto~4.6son top of balanced discover and did not improve top-10 Jaccard overlap in either benchmark query. - For baseline preservation,
qualityis the best default non-native rank mode. - For
api gateway, the strongest upgrade from native wasdiscover-balanced-blended-quality-heavy. - For
terminal ui, the strongest upgrade from native wasdiscover-balanced-quality. - For maximum semantic expansion,
querystill introduces the most novelty, but it sheds much more of the native core.
Recommendation Matrix
| Goal | Recommended Option | Why it wins in this study | Do not choose it when… |
|---|---|---|---|
| Fastest safe default | native-best-match | It is the only consistently sub-second path and remains the reference baseline for all comparisons. | You explicitly want semantic expansion or explain-driven ranking behavior. |
| Cheapest discover path | discover-quick-native | It preserves the native top 10 while showing the minimum discover-depth tax. | You need additional novelty, because quick-native bought cost without result-set change in this run. |
Best upgrade from native for api gateway | discover-balanced-blended-quality-heavy | It kept 8/10 of the native top 10, retained 5/5 of the native top five, and raised quality without paying deep-mode cost. | You primarily want novel repositories instead of a curated upgrade to the baseline set. |
Best upgrade from native for terminal ui | discover-balanced-quality | It matched the best non-native Jaccard (0.4286), retained 4/5 of the native top five, and was cheaper than quality-heavy. | You want maximum semantic drift or query-heavy expansion. |
| Strongest semantic expansion | discover-balanced-query | It produced 6 novel results on both benchmark queries and maximized semantic movement within the balanced family. | You care about preserving the native core, because it kept only 1/5 of the native top five on both queries. |
| Practical middle ground | discover-balanced-blended | It is often the balanced family’s cheapest general mode and usually sits near the frontier between cost and novelty. | You need stronger baseline fidelity than a 0.25 to 0.3333 Jaccard result can offer. |
| Freshest repository slice | discover-balanced-activity --updated-within 1y | It is the discover path if recency is more important than baseline stability. | You expect it to behave like default search. The recency slice introduced 5 to 6 novel results and materially changed the set. |
| Language-constrained search | native-rust first, then discover-balanced-blended --language Rust only if needed | Native filtering is extremely cheap. The discover Rust slice is only useful when semantic expansion inside the language slice matters. | You want general-purpose search. The Rust slice is intentionally far from the default baseline. |
| README-aware investigation | --readme only as an explicit second pass | It guarantees README evidence in explain output and can help inspect why a result matched. | You are optimizing for latency or top-10 stability. It added cost without improving top-10 overlap in this benchmark. |
Cost Ladder
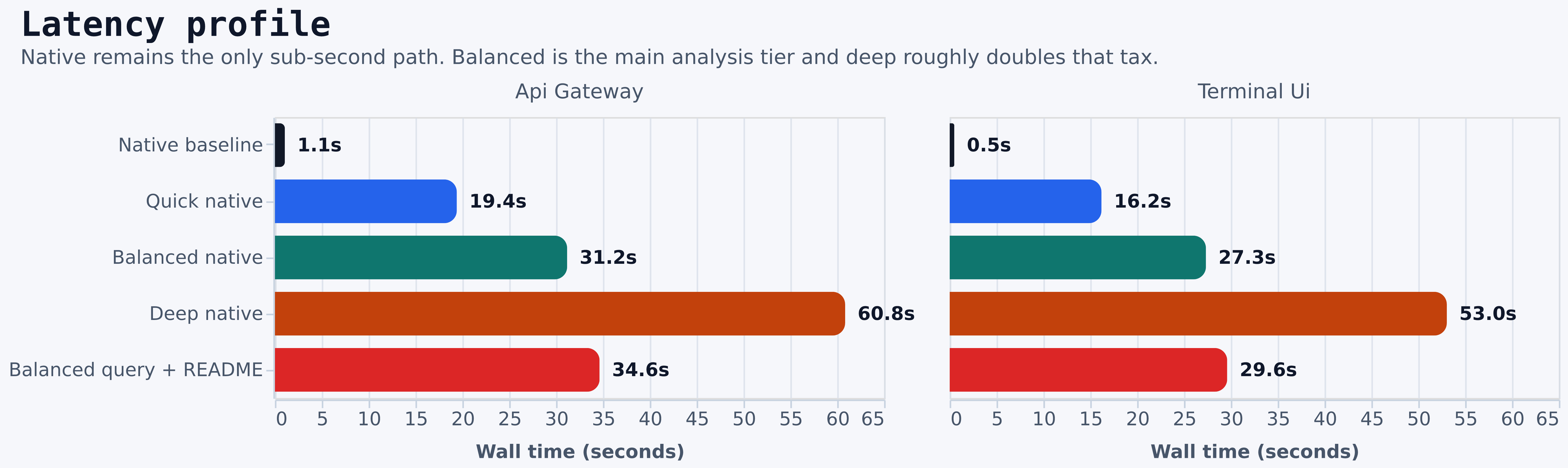
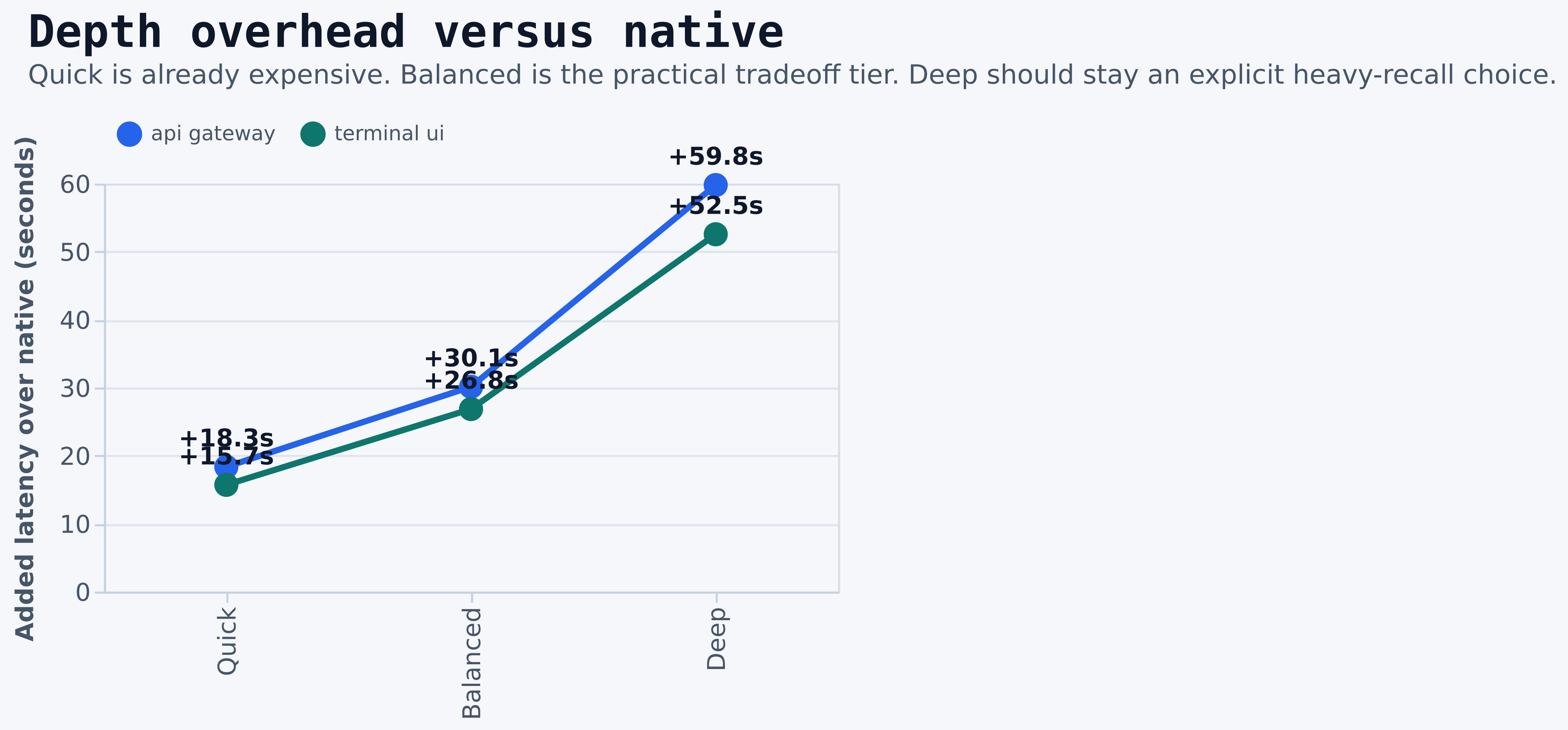
- Native is the only low-latency mode.
- Quick discover is already a substantial tax. Treat it as a deliberate opt-in, not a near-native fallback.
- Balanced discover is the practical analysis tier. It is slow enough to matter, but still much cheaper than deep.
- Deep discover is expensive enough that it should be reserved for deliberate heavy-recall workflows.
- README enrichment is not free. In this study it added
~11%to~15%on top of balanced discover while leaving top-10 overlap unchanged.
| Query | Quick over native | Balanced over native | Deep over native | README tax range |
|---|---|---|---|---|
api gateway | +18.3s | +30.1s | +59.8s | +3.5s to +4.6s |
terminal ui | +15.7s | +26.8s | +52.5s | +2.9s to +3.9s |
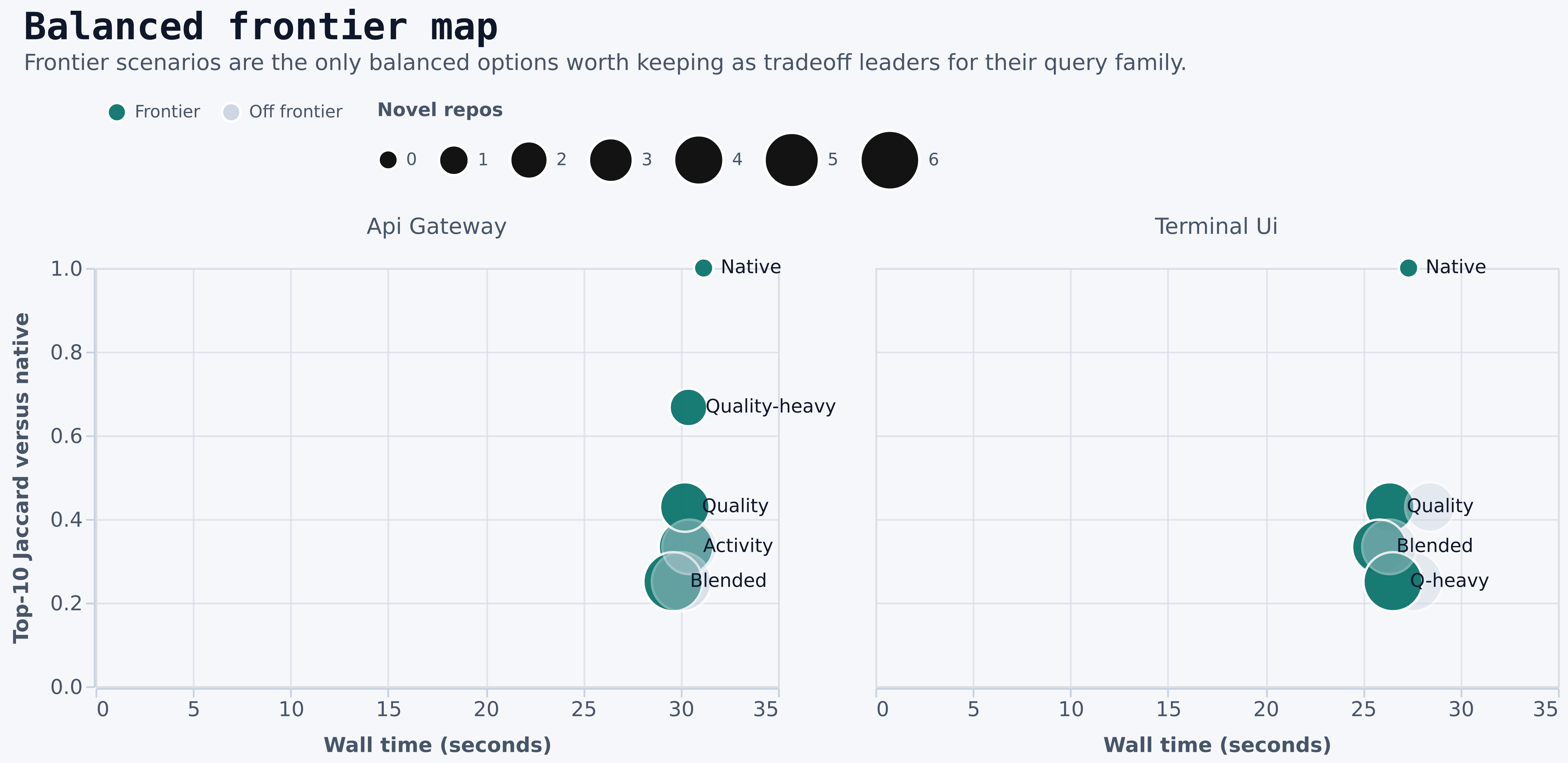
Balanced Decision Zone
Balanced discover is where the real product tradeoffs live. It is the family most likely to be exposed as the default advanced mode, so it deserves deeper inspection than the raw run table.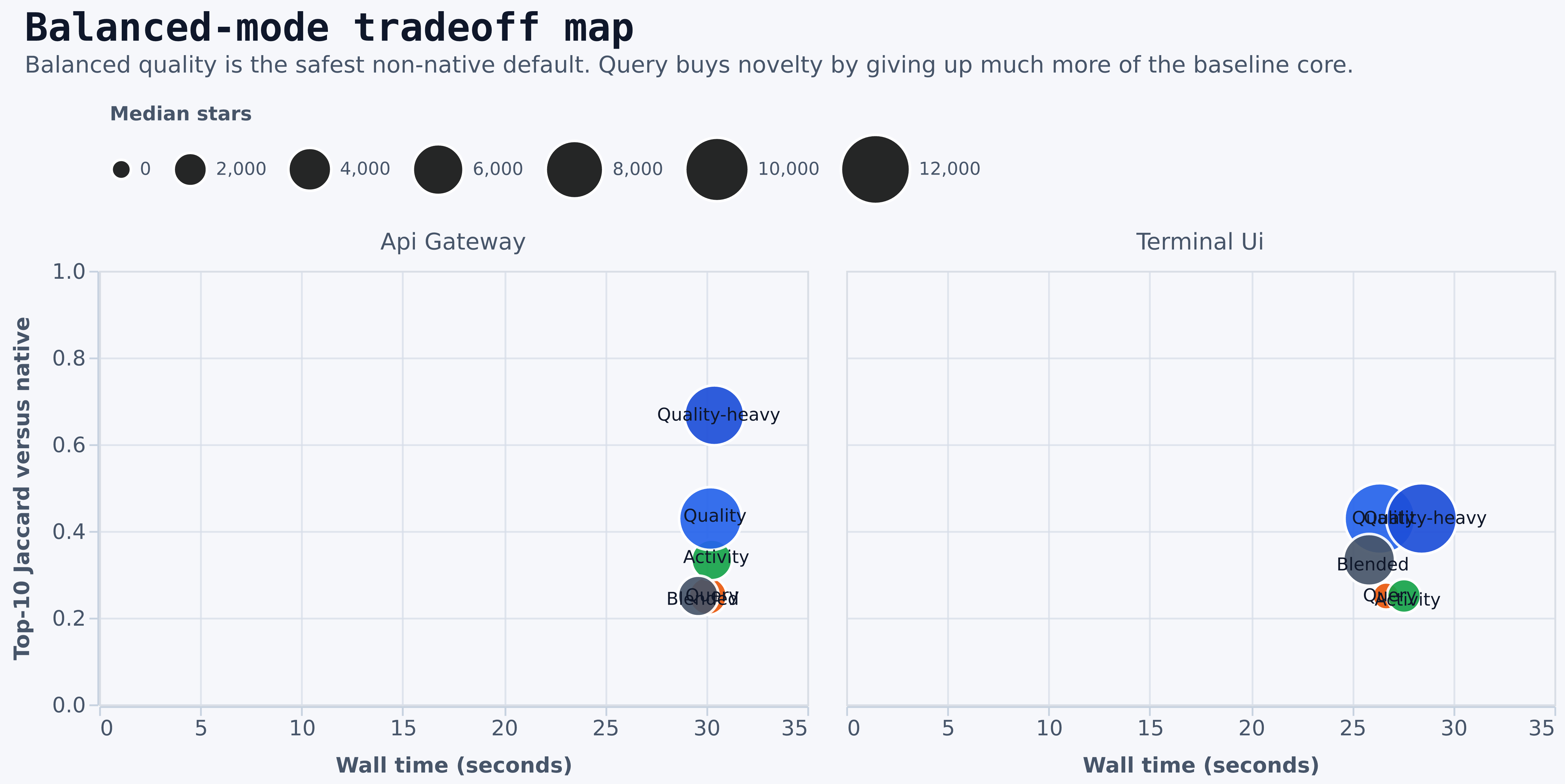
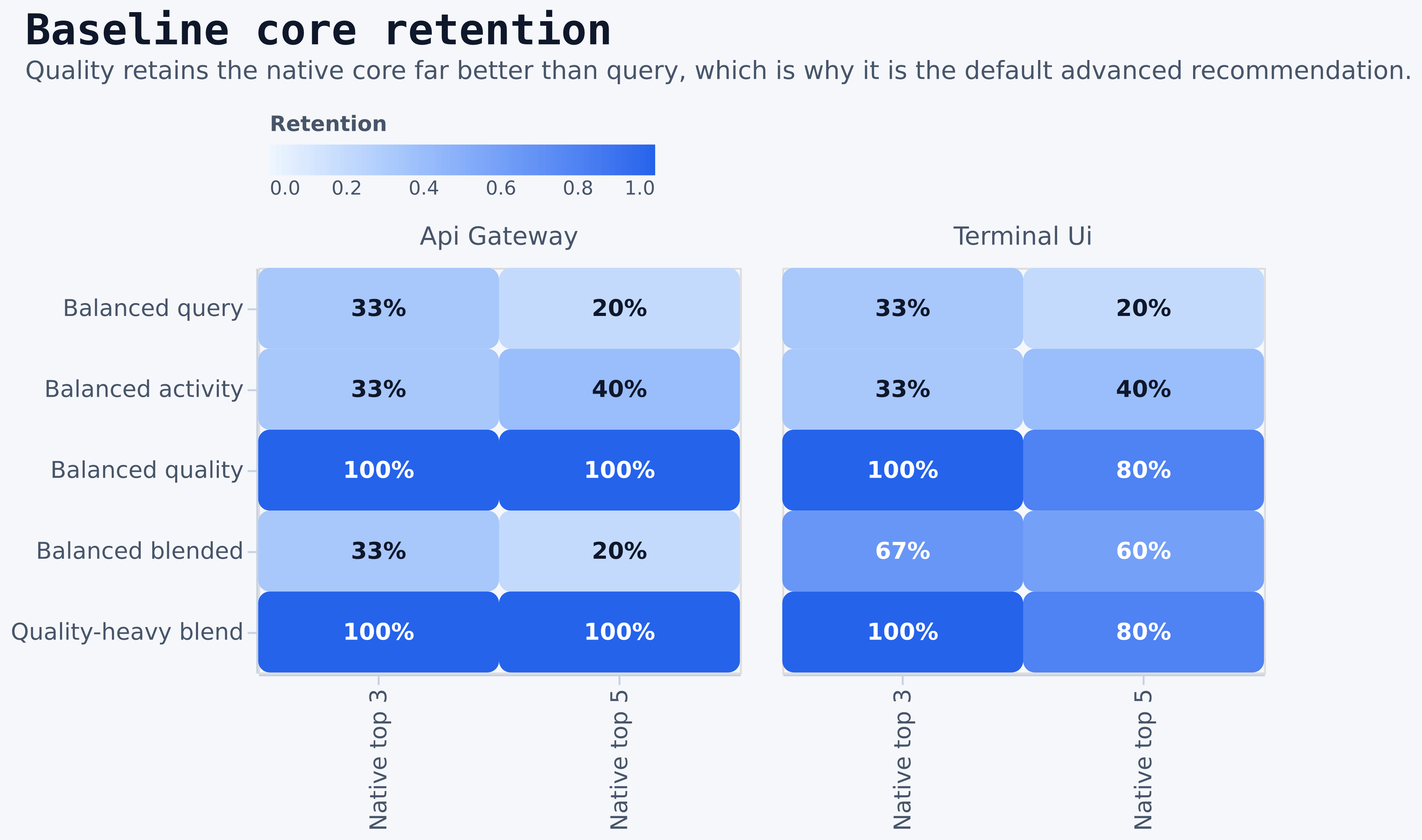
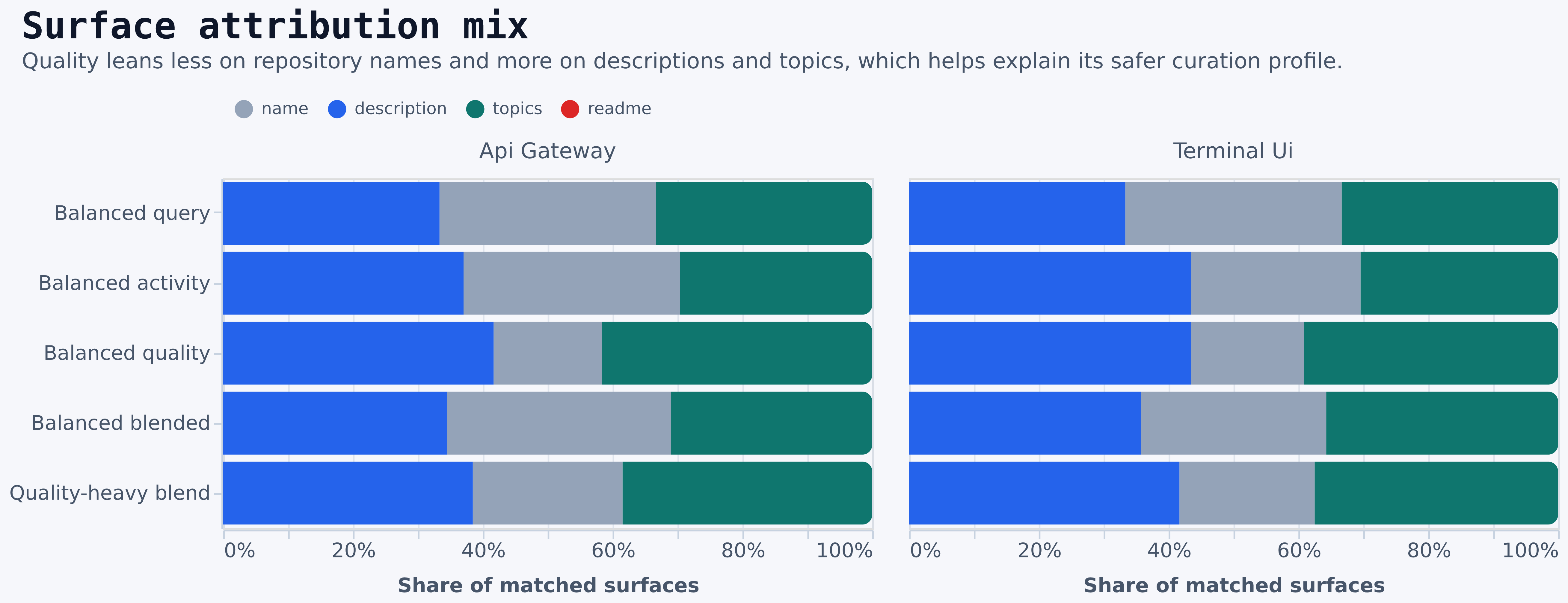
report.md, paired-effects.csv, and scenario-analysis.csv.
What these views show:
qualityandquality-heavypreserve the native core far better thanquery.blendedis often the cheapest balanced choice, but its top-10 fidelity is materially lower thanquality.queryis not the best frontier choice in this run. It is dominated by cheaper alternatives with equal or better novelty tradeoffs in key cases.quality-heavyis especially strong onapi gateway, where it preserves the native core while improving repository quality signals.- The surface-mix chart explains why:
qualityleans less on repository names and more on description and topic evidence.
- On
api gateway, the balanced frontier includesnative,activity,quality,blended, andquality-heavy. - On
terminal ui, the balanced frontier includesnative,quality,blended, andquery-heavy. discover-balanced-queryis not on the balanced frontier for either benchmark query.- README variants are off the frontier in this run because they add cost without improving top-10 fidelity.
Ranking Mode Guidance
The rank mode is the real behavior selector. Depth mostly controls cost. Rank controls what sort of repositories survive the cut.| Rank mode | What it tends to optimize | Strengths in this study | Weaknesses in this study | Best use |
|---|---|---|---|---|
native | Preservation of the original GitHub result set | Perfect overlap with the native baseline at any discover depth | You pay discover latency without changing the result set | Sanity checks, pipeline validation, and baseline-preserving comparisons |
query | Maximum lexical and semantic expansion | Highest novelty in balanced mode, with 6 novel results on both benchmark queries | It retained only 1/5 of the native top five on both queries | Exploratory search when broad expansion matters more than fidelity |
activity | Fresher, more active repositories | Useful when you deliberately want newer movement and more churn | It did not beat quality as a general default and still paid balanced latency | Recency-focused or trend-seeking workflows |
quality | Higher-quality, more established repositories | Best default non-native rank for preserving the native core while improving median stars | Less novelty than query, and can stay conservative | Default advanced ranking when you want better curation without losing the core set |
blended | Middle ground across query, activity, and quality | Usually one of the cheapest balanced options and often frontier-competitive | Default blended weights were weaker than quality for baseline preservation | General-purpose discover when you want some novelty without going full query mode |
Knob Guidance
| Option | What it does | What the study says | Practical guidance |
|---|---|---|---|
--depth quick | Reduces candidate expansion relative to balanced and deep | Still expensive over native, but much cheaper than deep | Use only when you want the cheapest discover proof point |
--depth balanced | Middle ground between recall and cost | Best general operating point for comparison, tradeoff tuning, and explain analysis | Treat this as the default experimental tier |
--depth deep | Maximum candidate expansion | Roughly doubles the balanced tax without proportional gains in these two queries | Reserve for explicit high-recall investigations |
--readme | Adds README evidence to explain and matching | Added ~3s to ~5s without top-10 gains in this run | Keep it as a targeted second pass, not the default |
--weight-query heavy | Pushes blended toward query-driven novelty | Helpful on terminal ui, where query-heavy reached the frontier | Use when plain blended feels too conservative |
--weight-activity heavy | Pushes blended toward recency and activity | Weak general payoff in this run | Use only with a clear freshness objective |
--weight-quality heavy | Pushes blended toward higher-quality repositories | Very strong on api gateway, where it became the best non-native upgrade from baseline | Good option when you want a safer upgrade than raw query |
--updated-within 1y | Forces recency slice | Produces high churn and should be treated as a different intent, not a small tweak | Use only when freshness is a hard requirement |
--language Rust | Narrows search to a language slice | Cheap natively, expensive under discover, and intentionally far from default search | Start with native language filtering, then add discover only if needed |
Query-Specific Findings
api gateway
discover-balanced-blended-quality-heavywas the best non-native compromise.- It kept
8/10of the native top 10 and5/5of the native top five. discover-balanced-qualityalso retained the full native top five, but with less baseline overlap thanquality-heavy.discover-balanced-queryanddiscover-balanced-blendedboth delivered6novel results, but each kept only1/5of the native top five.- README enrichment added
+3.5sto+4.6sand did not improve top-10 Jaccard.
terminal ui
discover-balanced-qualitywas the best non-native default.- It kept
4/5of the native top five with0.4286Jaccard and remained cheaper thanquality-heavy. discover-balanced-blendedsat on the frontier because it was cheaper and still delivered5novel results.discover-balanced-blended-query-heavyalso sat on the frontier and dominated plaindiscover-balanced-queryin this run.- README enrichment added
+2.9sto+3.9sand again did not improve top-10 Jaccard.
Churn And Stable Leaders
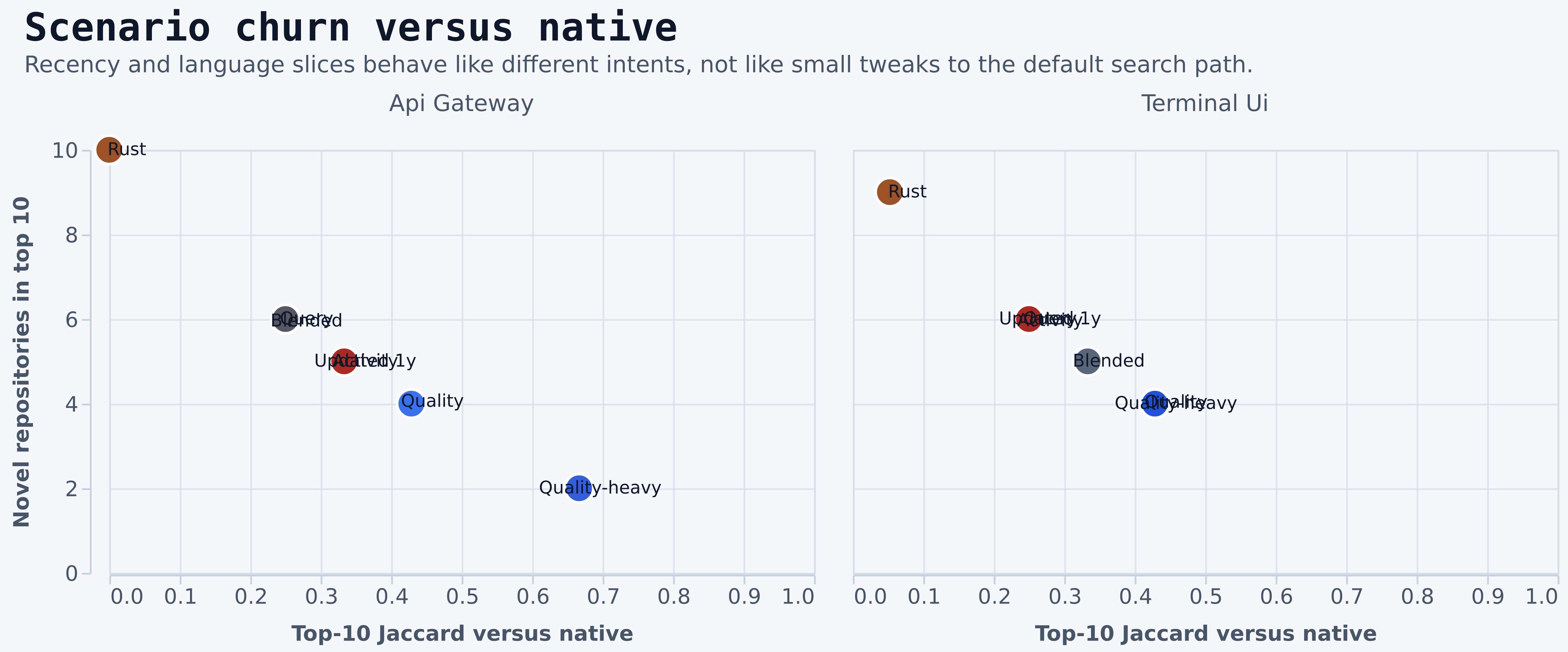
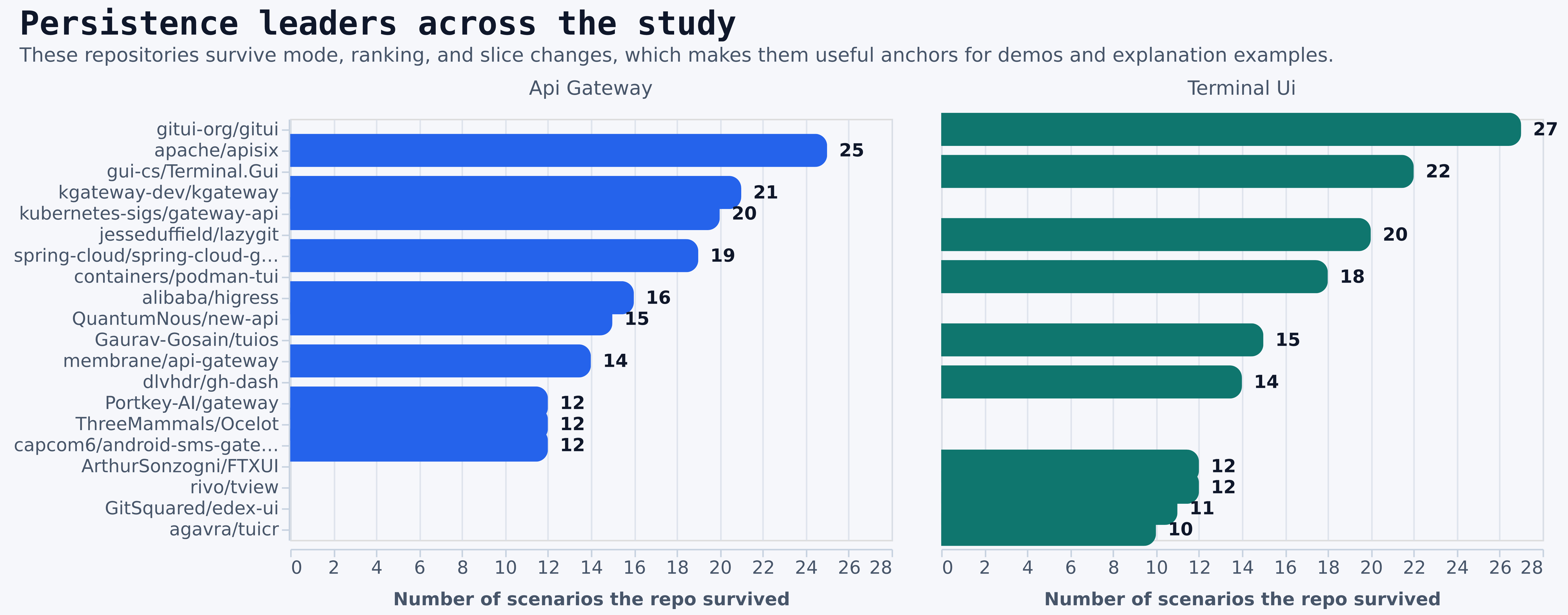
- The churn chart tells you which options are still “about the same search” versus which ones are effectively different products.
- The persistence chart shows which repositories survive almost every mode and filter change.
- Persistent leaders are especially useful for screenshots, demo flows, and explanation examples because they are less likely to disappear when the ranking strategy changes.
How To Run The Study
The benchmark harness lives at: Build the binary first if needed:GITQUARRY_TOKEN is not set, the runner will try to use GitHub CLI auth before failing.
Operator Playbook
If the goal is to help an operator choose a mode quickly, use these presets instead of re-reading the full study every time:| Operator intent | Recommended command pattern | Why |
|---|---|---|
| Fastest default | gitquarry search "<query>" | Keeps latency near the native baseline. |
| Safer discover upgrade | gitquarry search "<query>" --mode discover --depth balanced --rank quality --explain | Best default non-native mode when you want better curation without throwing away the baseline core. |
| Broader semantic exploration | gitquarry search "<query>" --mode discover --depth balanced --rank query --explain | Highest novelty in the balanced family. |
Better curated api gateway-style results | gitquarry search "<query>" --mode discover --depth balanced --rank blended --weight-query 0.5 --weight-activity 0.5 --weight-quality 2.0 --explain | This is the quality-heavy shape that performed best on the noisier benchmark query. |
| Fresh repos only | gitquarry search "<query>" --mode discover --depth balanced --rank activity --updated-within 1y --explain | Use when freshness is a hard requirement and churn is acceptable. |
| Language slice first | gitquarry search "<query>" --language Rust | Start cheap. Only add discover after confirming the slice is worth exploring semantically. |
| README inspection pass | gitquarry search "<query>" --mode discover --depth balanced --rank quality --readme --explain | Use as a second pass when you need richer evidence, not as the default query path. |
- Start with native if latency matters most.
- Move to balanced
qualityif you need a smarter curated set. - Move to balanced
queryonly when you explicitly want more novel repositories. - Add
--readme,--updated-within, or--languageonly when the task requires that specific constraint.
Output Files
The study writes raw and derived artifacts totarget/benchmark-study/.
Most useful outputs:
run-summaries.csvcomparisons.csvscenario-analysis.csvpaired-effects.csvbalanced-frontier.csvrepo-rows.csvreport.mdraw/<query>/<scenario>.json
docs/images/benchmark-study/ as direct Altair and Vega-Lite renders in both SVG and high-resolution PNG form. The CSV and markdown artifacts remain the exact source of truth for benchmark values.
How To Read The Data
Use the artifacts in this order:- Start with
report.mdfor the headline summary. - Use
paired-effects.csvfor the cleanest latency-tax and delta analysis. - Use
scenario-analysis.csvfor decision metrics such as core retention, surface shares, and frontier flags. - Use
repo-rows.csvwhen you need exact repository-level evidence, scores, and matched surfaces.
Confidence Limits
This is a strong directional benchmark, not a universal law.- It uses two live queries, not a full benchmark corpus.
- It is a single-run live benchmark against GitHub data that changes over time.
- Latency is affected by network and GitHub response conditions.
- The top-10 overlap metrics are decision-useful, but they do not capture every ranking-quality dimension.
- README enrichment may pay off more on other query classes even though it did not change top-10 overlap here.